Java
Hibernate
Native SQL
Our own project
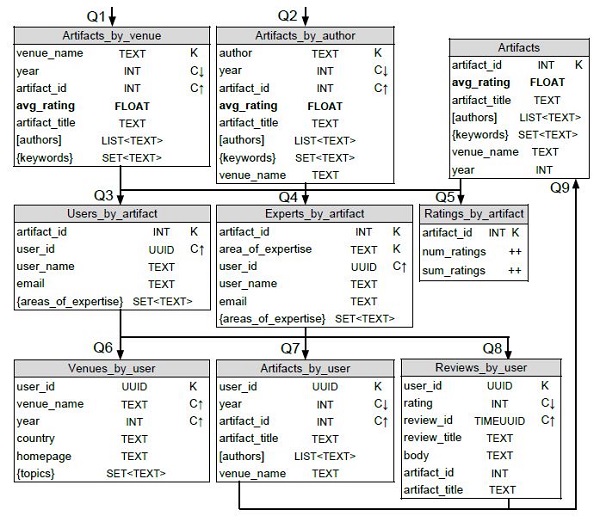
We recognized a crucial need for a robust database replication tool within our own organization to efficiently manage and synchronize data across multiple databases. This tool had to be versatile, capable of handling complex database structures, while providing comprehensive functionality.
To address this internal need, we carefully designed and developed a custom database replication tool. Our solution was built on the Java platform, incorporating Hibernate for ORM (Object-Relational Mapping), native SQL for optimized database interactions, and metadata handling. This tool featured one-to-one and potential one-to-many mapping capabilities, allowing us to efficiently replicate data across various database schemas. As an extra feature, we implemented high parallelism, supporting up to 100 concurrent connections for simultaneous data replication.
The development and implementation of this in-house database replication tool had a profound impact on our organization's data management capabilities and also costs. It spared us from buying expensive, single purpose hardware and significantly improved our ability to synchronize data across multiple databases seamlessly and efficiently using cost effective alternatives. This tool proved to be a valuable asset in maintaining data consistency and reliability, ultimately enhancing our overall operational efficiency. Its versatile functionality and high parallelism allowed us to manage complex data replication tasks with ease. Overall, this tool has served us exceptionally well, addressing our internal needs effectively and contributing to our operational success.